Earlier this year, the UDig Nashville office fielded a team to participate in Tractor Supply Company’s “Life out Here” AI/ML Hackathon and won the Product Recommendations competition! Hackathons are always a terrific way to try out modern technologies and build new skills, and it was a great experience for the whole team.
Problem and Approach
Below is the problem that our team was working to solve.

Our team wanted to use an a priori approach that did not rely on making assumptions about what data would and would not be valuable and instead tried to make use of all the data provided. This was especially appropriate because the customer history data provided was scrubbed of all semantic context. While for that customer data, we only had the IDs of the items clicked, added, or purchased by a specific customer at a location and date. For weather data, we were given a substantial number of attributes. By not relying on domain knowledge of weather’s impact on the sales, which our team did not have, we were able to make much better use of what was available to us.
Technologies
We chose to rely on Databricks as our platform to do data analysis and produce recommendations using PySpark and Scala. We used the
Databricks is an excellent tool as it is easy to set up a cloud instance with no prior experience or knowledge and pull in a variety of great tools and libraries for machine learning and data analytics. It has the extra benefit of requiring no local setup. It is simple to share work and for others to contribute with minimal hassle.
Our Solution
We divided our project into three parts: a customer processor that produced rules for customer purchase history-based recommendations, a weather processor that produced location and weather-based recommendations, and a recommendation engine that prioritized those recommendations for a given set of customers and locations.
Our customer recommendations used the previously mentioned market basket analysis with FP Growth as our algorithm of choice to produce rules. This algorithm uses prior purchase patterns to create rules around past purchase history. We chose FP-Growth over other association algorithms due to its speed, as some other a priori methods can become extremely slow with large volumes of data. Still, FP-Growth is efficient at eliminating weaker associations to prevent unnecessary data processing. In the below snippet, the antecedent represents item IDs that have been purchased in the past. The consequent is a likely future purchase, with the confidence, lift, and support providing various metrics of the strength of that association rule.
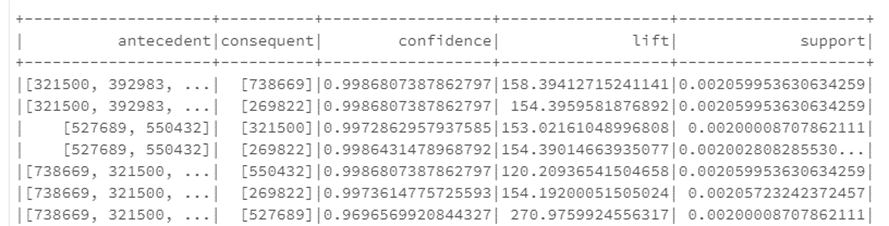
For example, the third record there represents a rule that if customers have purchased items 527689 and 550432, a good recommendation would be item 321500 or 269822, given that there is high confidence and lift value for those two rules. The lift value is also what we used as a weighting metric to prioritize the recommendations later. The customer processor then cleaned this list of association rules, dropping off low lift rules and attaching them to existing customer data to produce actual item recommendations.
For our weather and location processors, we wanted to produce similar ratios for weighting recommendations to the lift value from the customer processor so that we could prioritize the comprehensive list of recommendations. In general, we were happy to see customer-based recommendations have higher weightings. We expected them to be more predictive of purchasing behavior generally than the weather or location-based recommendations. However, we still wanted to ensure that location and weather data provided significant value.
The first problem with analyzing weather data was its size; we had a year’s worth of daily weather history with over 40 attributes (such as average temperature, precipitation level, relative humidity, air pressure, etc.). Running multiple linear regressions across these attributes on the purchase data would be computationally impractical, so we chose to simplify the data by categorizing the weather data into clusters. These clusters could then be analyzed to see purchase patterns and produce recommendations for future days based on weather forecasting; the cluster that a future day’s weather fell into would allow us to serve that weather cluster’s product recommendations to a customer.
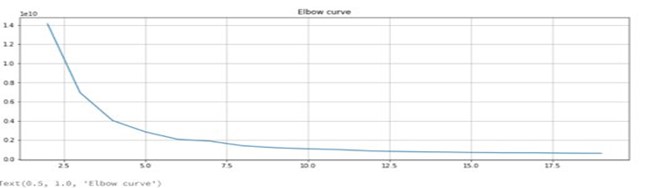
Firstly, we had to vectorize our complex weather data to produce a single vector value for each weather day per location, using PySpark’s built-in ML library’s VectorAssembler. Then we needed to determine how many clusters to use. We chose to use the elbow method to determine the optimal number of clusters, which ended up being 5.
Then with the k-means algorithm, we generated 5 clusters of weather data for each region, and then analyzed the purchase history of each cluster by comparing each item’s share of purchases within a cluster to its share of purchases within all clusters at a location. This gave us a ratio of how much more frequently that item was purchased with a particular weather cluster. After eliminating outliers with too little purchase frequency, we could use this ratio to provide weather-based recommendations.
A similar process without clustering was done for a location-based recommendation. We were looking for items with a higher proportion of purchases at a specific location relative to all locations.

With these three sets of recommendation rules in place, we were able to then build a recommendation engine that accepted customer IDs and weather forecasts to produce tailored and prioritized recommendations for those customers.

Future Ideas
Our current solution was intended to be run daily to update customer, weather, and location rules for use, which could then be used by any other system at TSC. Interesting future possibilities could include more descriptive attributes of items being involved to see if purchase patterns by item categories or descriptors could be found in interactions with weather and location data. Additionally, beyond just using the past historical weather data, past weather forecasts could also be used to see how they impacted purchasing; perhaps not only the existence of a weather phenomenon like rain but the past prediction could drive customer behavior.
Thank You
Big thanks to the rest of the UDig team that participated in the hackathon; Jessica Osekowsky, Page Schmidt, Matt Dean, and the whole Nashville UDig office that helped with ideas and feedback. We appreciate all the sponsors of the “Life out Here” hackathon, including CDW, who provided our prize, and most of all, to Tractor Supply Company for all their efforts in organizing and hosting the hackathon!

