Are you curious about all the new data technologies on the market? Are you looking to determine if you need a data warehouse, a data lake, or a data lakehouse? Are there fundamental differences, or is it just a marketing spin? The difference is real, and we’re here to give you a no-nonsense understanding of each and where they work best.
Data Warehouse
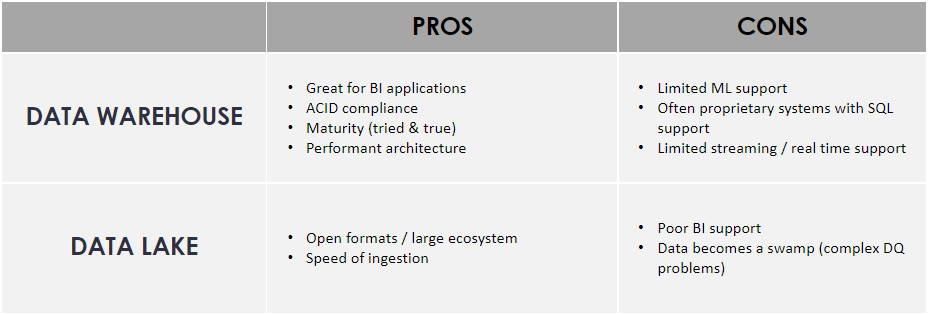
Traditional business intelligence (BI) workloads involved creating architectures built upon explicitly structured data. The data warehouse was devised as a shift from transactional to analytical systems. At its core, the data warehouse served to reliably store and access large amounts of data in a tabular manner. But as technology progressed, more and more varieties and formats of data became available for analysis that did not fit into the narrow paradigm of traditional data warehousing. As ‘big’ data exploded onto the scene, many new data sources were incompatible with the restrictions of the humble data warehouse, and for that innovation was needed.
Data Lake
Data lakes were created with these deficits in mind. The ability to store raw data formats cheaply led to an explosion in the capabilities of data analysts and data scientists, but not without its drawbacks. In many cases, as more and more data were added to the lake, it became swampy as data quality issues arose. The unrestricted nature of ‘throwing everything into the lake’ made for quick access and nearly unbounded means of analysis, but this was at the cost of the overhead of maintaining a system not designed to be easily maintained. Questions arose like: What is the source of truth? Who owns this data? Is this data set the most up to date?
The bottom line is that the data warehouse and the data lake are individually suited to be the most performant upon a narrow set of requirements. But the future is unpredictable; new innovations are needed as new problems are presented. Wouldn’t it be nice if we could harness the benefits of both the data lake and the data warehouse without having to worry about each of their respective drawbacks?
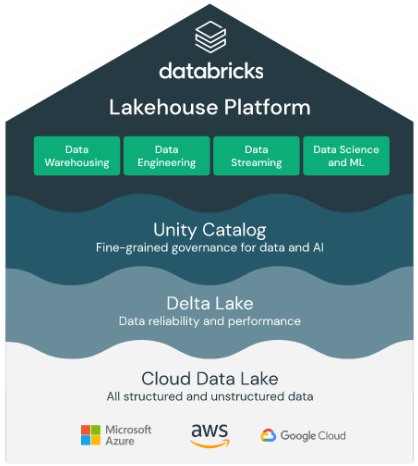
Databricks Lakehouse
The Databricks Lakehouse unifies the best of data warehouses and data lakes into a single platform. With a focus on reliability, performance, and strong governance, the Lakehouse approach simplifies the data stack by eliminating data silos that traditionally complicate data engineering, analytics, BI, data science, and machine learning.
Delta Lake is the foundation and open format data layer that allows Databricks to deliver reliability, security, and performance. The Delta Lake ensures delivery of a reliable single source of truth for your data, including real-time streaming. It supports ACID transactions (Atomicity, Consistency, Isolation, and Durability) and schema enforcement. All data in the Delta Lake is stored in Apache Parquet format, allowing data to be easily read and consumed. APIs are open source and compatible with Apache Spark.
Databricks clusters are a set of computational resources and configurations you use to run your workloads, such as ETL pipelines, machine learning, and ad-hoc analytics. Databricks offers all-purpose and job cluster types. Many users can share all-purpose clusters to do collaborative analytics. They can manually be terminated and can be restarted. The job scheduler specifically creates job clusters to run a job. They terminate when the job is completed and cannot be restarted. When you create a Databricks cluster, you either provide a fixed number of workers or a minimum and a maximum number of workers. The latter is referred to as autoscaling. With autoscaling, Databricks dynamically reallocates workers to your job and removes them when they are no longer needed. Autoscaling makes it possible to achieve a higher level of cluster utilization.
Databricks product components include collaborative workbooks that support multiple languages and libraries such as SQL, R, Python, and Scala so data engineers can work together on discovering, sharing, and visualizing insights. Other product components for Data Science and Machine Learning include the Machine Learning Runtime with scalable and reliable frameworks such as PyTorch, TensorFlow, and scikit-learn. Choose from integrated development environments (IDE) like RStudio or JupyterLab seamlessly within Databricks or use your favorite and connect. Use Git repos to leverage continuous integration and continuous delivery (CI/CD) workflows and code portability. And AutoML, MLflow, and Model Monitoring will help to deliver the highest quality model and ensure they can quickly promote from exploratory and experimentation to production with the security, scale, monitoring and performance they need.

